体系结构概述
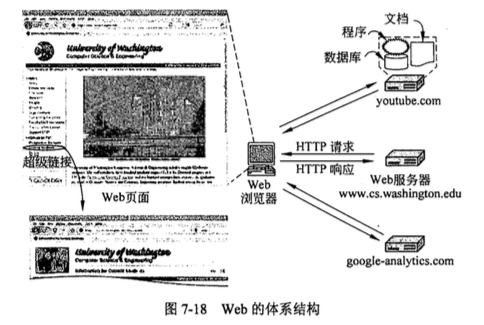
客户机器上的浏览器正在显示 一个 Web 页面。每一页的抓取都是通过发送一个请求到一个或多个服务器,服务器以页面 的内容作为响应。抓取网页所用的“请求.响应”协议是一个简单的基于文本协议,它运行 在 TCP 之上,就像 SMTP 一样。这个协议就是所谓的超文本传输协议( HTTP, HyperText Transfer Protocol )。内容可能只是一个磁盘读取的文档,或者是数据库查询和程序执行的结 果。如果每次显示的是相同的一个文档,则称该网页为静态页面(static page)。相反,如 果每次显示的是程序按需产生的内容,或者页面本身包含了一个程序,则称该网页为动态 页面 Cd归缸nic page)。
客户端
统一资源定位符(URL, UniformResourceLocator),用来有效地充当该页面在 全球范围内的名字。 URL包括3个部分:协议(也称为方案(scheme》、页面所在机器的 DNS 名字,以及唯一指向特定页面的路径〈通常是读取的一个文件或者运行在机器上的 一 个程序)。
http : //www.cs.washington.edu/index.html
这个 URL 由 3 部分组成:协议( http、主机的 DNS 域名 Cwww.cs.washington.edu) 和路径名( index.html)o

当用户点击一个超链,浏览器就执行一系列的步骤来获取该超链指向的网页。让我们 跟踪点击例子中链接时所发生的步骤:
(1)浏览器确定 URL C通过观察选中的什么〉。
(2)浏览器请求 DNS 查询服务器 www.cs.washington.edu 的 IP地址。
(3) DNS 返回 128.208.3.88。
(4)浏览器与 128.208.3.88 机器的 80 端口建立一个 TCP 连接, 80 端口是 HTTP 协议 的知名端口。
(5)浏览器发送 HTTP 报文,请求/index.html 页面。
(6) www.cs.washington.edu 服务器发回页面作为 HTTP 响应,例如发送文件/index. html。
(7)如果该页面包括需要显示的 URL,那么浏览器经过同样的处理过程获取其他 URL。 在这种情况下, URL 包括多
个取自 www.cs.washington.edu 的内嵌图像、一个取自 youtobe.com 的内嵌视频和一个取自 google-analyics.com
的脚本。
(8)浏览器显示页面/index.html
(9)如果短期内没有向同一个服务器发出其他请求,那么释放 TCP 连接。
服务器端
当用户键入一个 URL 或者单击一行超文本时,浏览器会解析 URL,并且将 http://和下 一个斜线之间的那部分解释成待查找的 DNS 名字。有了服务器的 IP 地址以后,浏览器与 该服务器的端口 80 建立一个 TCP 连接:然后它发送一条命令,其中包含了 URL 的剩余部 分,即该服务器上某个页面的路径:最后服务器返回该页面供浏览器显示。
服务器在它的主循环中执行如下 步骤:
(1) 接受来自客户端(浏览器)的 TCP 连接。
(2) 获取页面的路径,即被请求文件的名字。
(3) 获取文件(从磁盘上)。
(4) 将文件内容发送给客户。
(5) 释放该 TCP 连接。
为了解决一次只能服务一个请求的问题,一种策略是将服务器设计成多线程模式 (multithreaded)。在其中一种设计方案中,服务器由一个前端模块(front-endmodule)和 k 个处理模块( processing module)组成,如图:
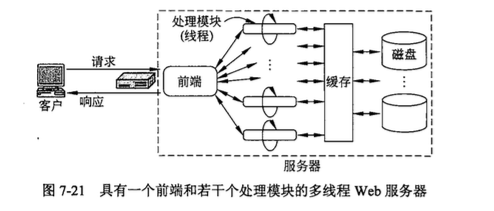
处理模块首先检查缓存,查看其中是否有所需的文件。如果缓存中有该文件,则处理 模块修改记录,在记录中增加一个指向该文件的指针:如果缓存中没有该文件,则处理模 块执行一次磁盘操作将该文件读入缓存(可能要丢弃其他一些缓存的文件,以便腾出空间)。 从磁盘上读取文件后,将该文件放入缓存,同时把它发送给客户。
现代 Web 服务器所做的不只是接受文件名和返回文件。在许多服务器中,每个处理模块要执行一系列步骤。 前端将每个入境请求传递给第一个可用模块,然后该模块根据这个特定请求的需要,执行 下列步骤中的某个子集。这些步骤发生在 TCP 连接和任何安全传输机制建立之后。
(1)解析被请求的 Web 页面的名字。
(2)执行对该页面的访问控制。
(3)检查缓存。
(4)从磁盘上获取请求的页面或者运行一个创建页面的程序。
(5)确定响应中的其余部分(比如要发送的阳ME 类型)。
(6)把响应返回给客户。
(7)在服务器的日志中增加 一个表项。
Cookie
